Fuzzing Tinybmp in Rust || From dumb to structure-aware guide
Introduction
In this blog post we will play around with some Rust code and fuzz the BMP header parsing methods within the TinyBMP Rust project. According to the project’s description:
A small BMP parser primarily for embedded, no-std environments but usable anywhere. This crate is primarily targeted at drawing BMP images to embedded_graphics DrawTargets, but can also be used to parse BMP files for other applications.
While I’ve been trying to learn Rust and understand a bit more about traits, I found this to be a perfect target as usually anything related to parsing might be prone to vulnerabilities. We will be starting off by reading the documentation of the project, setting up a simple (dumb) fuzzer and then move on to more interesting topic such as creating a structure-aware fuzzer. Hence if you haven’t done any fuzzing in Rust and looking for a beginner tutorial then hopefully this blog is for you! We will also be utilising cargo-fuzz , a cargo subcommand which uses libFuzzer (and needs LLVM sanitizer support). Before we move on, make sure to install it as per project instructions so you can follow along. As such, I will be using Kali 64bit for the rest of this tutorial.
Please note all of the discovered issues/bugs here have been reported already to the project owners and have been fixed!
This blog would also0 have not be possible without Addison’s (@addisoncrump_vr) help, which he provided guidance as well as the harness for the smart/structured-aware section which we will analyse in this blog!
Setting up the project
First things first, in order to be able to run cargo-fuzz you need to install the nightly version of rust (or switch to it):
$ rustup default nightly-x86_64-unknown-linux-gnu
info: using existing install for 'nightly-x86_64-unknown-linux-gnu'
info: default toolchain set to 'nightly-x86_64-unknown-linux-gnu'
nightly-x86_64-unknown-linux-gnu unchanged - rustc 1.67.0-nightly (73c9eaf21 2022-11-07)
$ rustup show
Default host: x86_64-unknown-linux-gnu
rustup home: /home/kali/.rustup
installed toolchains
--------------------
stable-x86_64-unknown-linux-gnu
nightly-2022-08-16-x86_64-unknown-linux-gnu
nightly-x86_64-unknown-linux-gnu (default)Let’s start by cloning the repo and reverting it prior the patches that have been added.
$ git clone https://github.com/embedded-graphics/tinybmp
Cloning into 'tinybmp'...
remote: Enumerating objects: 338, done.
remote: Counting objects: 100% (206/206), done.
remote: Compressing objects: 100% (142/142), done.
remote: Total 338 (delta 121), reused 94 (delta 59), pack-reused 132
Receiving objects: 100% (338/338), 175.67 KiB | 3.03 MiB/s, done.
Resolving deltas: 100% (162/162), done.Let’s limit the commit entries to 10:
$ git log -n 10
commit 8b4c2ced92a9ff16b5c534ca11c9877ff5d31a8d (HEAD -> master, tag: v0.4.0, origin/master, origin/HEAD)
Author: James Waples <james@wapl.es>
Date: Fri Sep 30 19:13:03 2022 +0100
(cargo-release) version 0.4.0
commit 955135693326b133dd6a333b97b4510f8060d4fe
Author: James Waples <james@wapl.es>
Date: Fri Sep 30 19:12:03 2022 +0100
Fix warning in release config
commit 132967379a1d16f2741f8dffdf423a21b4f34114
Author: James Waples <james@wapl.es>
Date: Fri Sep 30 19:10:51 2022 +0100
Add pixel getter examples (#37)
* Add pixel getter examples
* Apply suggestions from code review
Co-authored-by: Ralf Fuest <mail@rfuest.de>
commit c64e35ae19c8a7175aebcbc9a008d331f72b4d20
Author: Ralf Fuest <mail@rfuest.de>
Date: Fri Sep 30 17:11:52 2022 +0200
Check for integer overflows in RawBmp::parse (#32)
* Check for integer overflows in RawBmp::parse
* Don't allow images with zero width or height
* Check for negative width and add tests
* Reformat code
... snip ...
commit 815e9f99aa5ce053b4985572ea145f39758e78a5
Author: James Waples <james@wapl.es>
Date: Mon Apr 18 20:41:08 2022 +0100
(cargo-release) version 0.3.3We’re interested in reverting it to the version 0.3.3 so let’s do that:
┌──(kali㉿kali)-[~/Desktop/tinybmp]
└─$ git checkout -b old-state 815e9f99aa5ce053b4985572ea145f39758e78a5
Switched to a new branch 'old-state'
┌──(kali㉿kali)-[~/Desktop/tinybmp]
└─$ git log
commit 815e9f99aa5ce053b4985572ea145f39758e78a5 (HEAD -> old-state)
Author: James Waples <james@wapl.es>
Date: Mon Apr 18 20:41:08 2022 +0100
(cargo-release) version 0.3.3Creating a dumb fuzzer
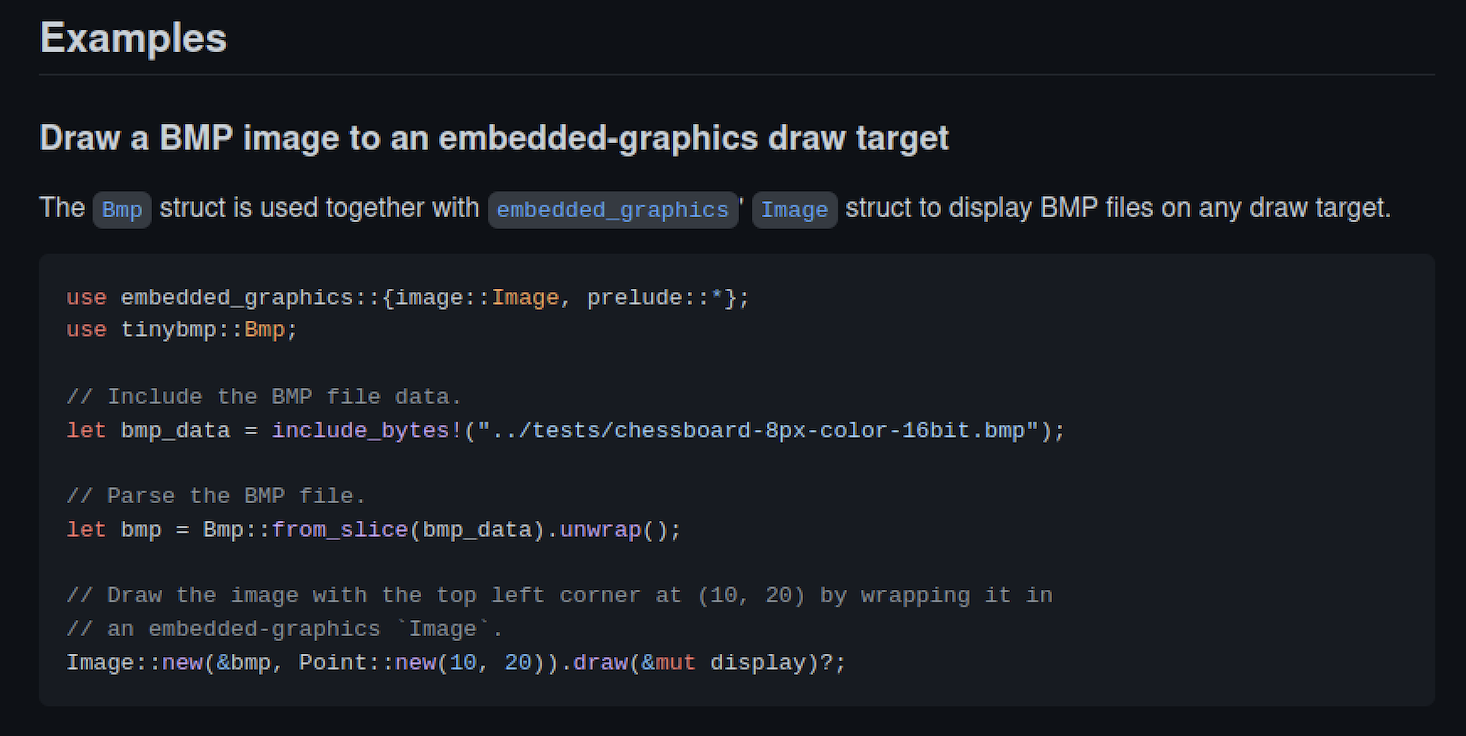
Now that we’ve setup the project it’s time to experiment and play around with the docs. Navigating through the project we can see the following sample code:
If you are coming from a winafl/AFL background naturally you’ll probably think that somehow you’ll need to figure out a way to provide a file input, mutate it and then pass the fuzzed file to the target. However, cargo-fuzz/LLVM works slightly different… remember its API is defined as:
// fuzz_target.cc
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
DoSomethingInterestingWithMyAPI(Data, Size);
return 0; // Values other than 0 and -1 are reserved for future use.
}Let’s compare that to cargo’s fuzz tutorial:
#![no_main]
#[macro_use] extern crate libfuzzer_sys;
extern crate url;
fuzz_target!(|data: &[u8]| {
if let Ok(s) = std::str::from_utf8(data) {
let _ = url::Url::parse(s);
}
});So the API is pretty much similar, in fact we only need to privide a closure with the parameter data which is going to be what cargo-fuzz will mutate.
Let’s init a new campaign, create a new project and name it dumb:
┌──(kali㉿kali)-[~/Desktop/tinybmp]
└─$ cargo fuzz init
┌──(kali㉿kali)-[~/Desktop/tinybmp]
└─$ cargo fuzz add dumb
┌──(kali㉿kali)-[~/Desktop/tinybmp]
└─$ cat fuzz/fuzz_targets/dumb.rs
#![no_main]
use libfuzzer_sys::fuzz_target;
fuzz_target!(|data: &[u8]| {
// fuzzed code goes here
});Cargo-fuzz has created some boilerplate code for us, let’s modify it similar to the provided example:
#![no_main]
use libfuzzer_sys::fuzz_target;
use embedded_graphics::{pixelcolor::Rgb888, prelude::*};
use tinybmp::Bmp;
fuzz_target!(|data: &[u8]| {
// Note: The color type is specified explicitly to match the format used by the BMP image.
let bmp = Bmp::<Rgb888>::from_slice(data).unwrap();
}); That looks like it might work, let’s try to run it:
$ cargo fuzz run dumb
Updating crates.io index
Downloaded libfuzzer-sys v0.4.5
Downloaded libc v0.2.137
Downloaded arbitrary v1.2.0
Downloaded 3 crates (763.8 KB) in 0.37s
-- snip --
Compiling tinybmp-fuzz v0.0.0 (/home/kali/Desktop/tinybmp/fuzz)
error[E0433]: failed to resolve: use of undeclared crate or module `embedded_graphics`
--> fuzz_targets/dumb.rs:3:5
|
3 | use embedded_graphics::{pixelcolor::Rgb888, prelude::*};
| ^^^^^^^^^^^^^^^^^ use of undeclared crate or module `embedded_graphics`
error[E0432]: unresolved import `embedded_graphics::pixelcolor::Rgb888`
--> fuzz_targets/dumb.rs:3:25
|
3 | use embedded_graphics::{pixelcolor::Rgb888, prelude::*};
| ^^^^^^^^^^^^^^^^^^
Some errors have detailed explanations: E0432, E0433.
For more information about an error, try `rustc --explain E0432`.
error: could not compile `tinybmp-fuzz` due to 2 previous errors
Error: failed to build fuzz script: "cargo" "build" "--manifest-path" "/home/kali/Desktop/tinybmp/fuzz/Cargo.toml" "--target" "x86_64-unknown-linux-gnu" "--release" "--bin" "dumb"That command failed, let’s add that crate to Cargo.toml and run it again:
[dependencies]
libfuzzer-sys = "0.4"
embedded-graphics = "0.7.1"└─$ cargo fuzz run dumb
Updating crates.io index
Downloaded libfuzzer-sys v0.4.5
Downloaded libc v0.2.137
Downloaded arbitrary v1.2.0
Downloaded 3 crates (763.8 KB) in 0.27s
Compiling libc v0.2.137
Compiling autocfg v1.1.0
Compiling az v1.2.1
Compiling byteorder v1.4.3
Compiling num-traits v0.2.15
Compiling micromath v1.1.1
Compiling jobserver v0.1.25
Compiling arbitrary v1.2.0
Compiling cc v1.0.73
Compiling libfuzzer-sys v0.4.5
Compiling float-cmp v0.8.0
Compiling embedded-graphics-core v0.3.3
Compiling embedded-graphics v0.7.1
Compiling once_cell v1.15.0
Compiling tinybmp v0.3.3 (/home/kali/Desktop/tinybmp)
Compiling tinybmp-fuzz v0.0.0 (/home/kali/Desktop/tinybmp/fuzz)
....
--> fuzz_targets/dumb.rs:3:45
|
3 | use embedded_graphics::{pixelcolor::Rgb888, prelude::*};
| ^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: unused variable: `bmp`
--> fuzz_targets/dumb.rs:8:9
|
8 | let bmp = Bmp::<Rgb888>::from_slice(data).unwrap();
| ^^^ help: if this is intentional, prefix it with an underscore: `_bmp`
|
= note: `#[warn(unused_variables)]` on by default
warning: `tinybmp-fuzz` (bin "dumb") generated 2 warnings
Finished release [optimized + debuginfo] target(s) in 0.90s
warning: unused import: `prelude::*`
--> fuzz_targets/dumb.rs:3:45
|
3 | use embedded_graphics::{pixelcolor::Rgb888, prelude::*};
| ^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: unused variable: `bmp`
--> fuzz_targets/dumb.rs:8:9
|
8 | let bmp = Bmp::<Rgb888>::from_slice(data).unwrap();
| ^^^ help: if this is intentional, prefix it with an underscore: `_bmp`
|
= note: `#[warn(unused_variables)]` on by default
warning: `tinybmp-fuzz` (bin "dumb") generated 2 warnings
Finished release [optimized + debuginfo] target(s) in 0.01s
Running `fuzz/target/x86_64-unknown-linux-gnu/release/dumb -artifact_prefix=/home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/ /home/kali/Desktop/tinybmp/fuzz/corpus/dumb`
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 485875195
INFO: Loaded 1 modules (11576 inline 8-bit counters): 11576 [0x558fe7ad9c10, 0x558fe7adc948),
INFO: Loaded 1 PC tables (11576 PCs): 11576 [0x558fe7adc948,0x558fe7b09cc8),
INFO: 24 files found in /home/kali/Desktop/tinybmp/fuzz/corpus/dumb
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
thread '<unnamed>' panicked at 'called `Result::unwrap()` on an `Err` value: UnexpectedEndOfFile', fuzz_targets/dumb.rs:8:47
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
==6168== ERROR: libFuzzer: deadly signal
#0 0x558fe787bfe1 in __sanitizer_print_stack_trace /rustc/llvm/src/llvm-project/compiler-rt/lib/asan/asan_stack.cpp:87:3
#1 0x558fe79593ca in fuzzer::PrintStackTrace() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerUtil.cpp:210:38
#2 0x558fe7922f15 in fuzzer::Fuzzer::CrashCallback() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:233:18
#3 0x558fe7922f15 in fuzzer::Fuzzer::CrashCallback() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:228:6
#4 0x7f828083da9f (/lib/x86_64-linux-gnu/libc.so.6+0x3da9f) (BuildId: 71a7c7b97bc0b3e349a3d8640252655552082bf5)
#5 0x7f828088957b in __pthread_kill_implementation nptl/./nptl/pthread_kill.c:43:17
#6 0x7f828083da01 in gsignal signal/../sysdeps/posix/raise.c:26:13
#7 0x7f8280828468 in abort stdlib/./stdlib/abort.c:79:7
#8 0x558fe79b4606 in std::sys::unix::abort_internal::h0897be309fb2baa9 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/sys/unix/mod.rs:293:14
#9 0x558fe77ee216 in std::process::abort::hc3bb2bc8d10060de /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/process.rs:2119:5
#10 0x558fe791d2b3 in libfuzzer_sys::initialize::_$u7b$$u7b$closure$u7d$$u7d$::hfbc7451104c5815a /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:91:9
#11 0x558fe79a960c in std::panicking::rust_panic_with_hook::h76fd95765866f4c4 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:702:17
#12 0x558fe79a9466 in std::panicking::begin_panic_handler::_$u7b$$u7b$closure$u7d$$u7d$::h60f8b3f90bb7fd93 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:588:13
#13 0x558fe79a667b in std::sys_common::backtrace::__rust_end_short_backtrace::h483cd9e52367386f /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/sys_common/backtrace.rs:138:18
#14 0x558fe79a9181 in rust_begin_unwind /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:584:5
#15 0x558fe77ef5a2 in core::panicking::panic_fmt::h44b4db96b14cf253 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/core/src/panicking.rs:142:14
#16 0x558fe77ef6f2 in core::result::unwrap_failed::hc10b6a87ebce4f5d /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/core/src/result.rs:1814:5
#17 0x558fe78b5d41 in core::result::Result$LT$T$C$E$GT$::unwrap::h7ffe31d9ddee89b2 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/core/src/result.rs:1107:23
#18 0x558fe78b5d41 in dumb::_::run::h93074574f0ae19de /home/kali/Desktop/tinybmp/fuzz/fuzz_targets/dumb.rs:8:15
#19 0x558fe78b51d8 in rust_fuzzer_test_input /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:224:17
#20 0x558fe791864f in libfuzzer_sys::test_input_wrap::_$u7b$$u7b$closure$u7d$$u7d$::h6b2b51dabd6d08ff /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:61:9
#21 0x558fe791864f in std::panicking::try::do_call::h2b6b2fecd8b0ff94 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:492:40
#22 0x558fe791d4e7 in __rust_try libfuzzer_sys.4efe2baf-cgu.0
#23 0x558fe791c868 in std::panicking::try::hf3b7ef749ee396d0 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:456:19
#24 0x558fe791c868 in std::panic::catch_unwind::hef97c053185a011b /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panic.rs:137:14
#25 0x558fe791c868 in LLVMFuzzerTestOneInput /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:59:22
#26 0x558fe7923449 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:612:15
#27 0x558fe792bcf2 in fuzzer::Fuzzer::ReadAndExecuteSeedCorpora(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:805:18
#28 0x558fe792c2e7 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:865:28
#29 0x558fe7942004 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerDriver.cpp:912:10
#30 0x558fe77ef9d2 in main /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerMain.cpp:20:30
#31 0x7f8280829209 in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
#32 0x7f82808292bb in __libc_start_main csu/../csu/libc-start.c:389:3
#33 0x558fe77efb10 in _start (/home/kali/Desktop/tinybmp/fuzz/target/x86_64-unknown-linux-gnu/release/dumb+0x72b10) (BuildId: efe97053d3a33c625fcf3451ca94dfe7e9bed6b7)
NOTE: libFuzzer has rudimentary signal handlers.
Combine libFuzzer with AddressSanitizer or similar for better crash reports.
SUMMARY: libFuzzer: deadly signal
MS: 0 ; base unit: 0000000000000000000000000000000000000000
artifact_prefix='/home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/'; Test unit written to /home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709
Base64:
────────────────────────────────────────────────────────────────────────────────
Failing input:
fuzz/artifacts/dumb/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709
Output of `std::fmt::Debug`:
[]
Reproduce with:
cargo fuzz run dumb fuzz/artifacts/dumb/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709
Minimize test case with:
cargo fuzz tmin dumb fuzz/artifacts/dumb/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709
────────────────────────────────────────────────────────────────────────────────
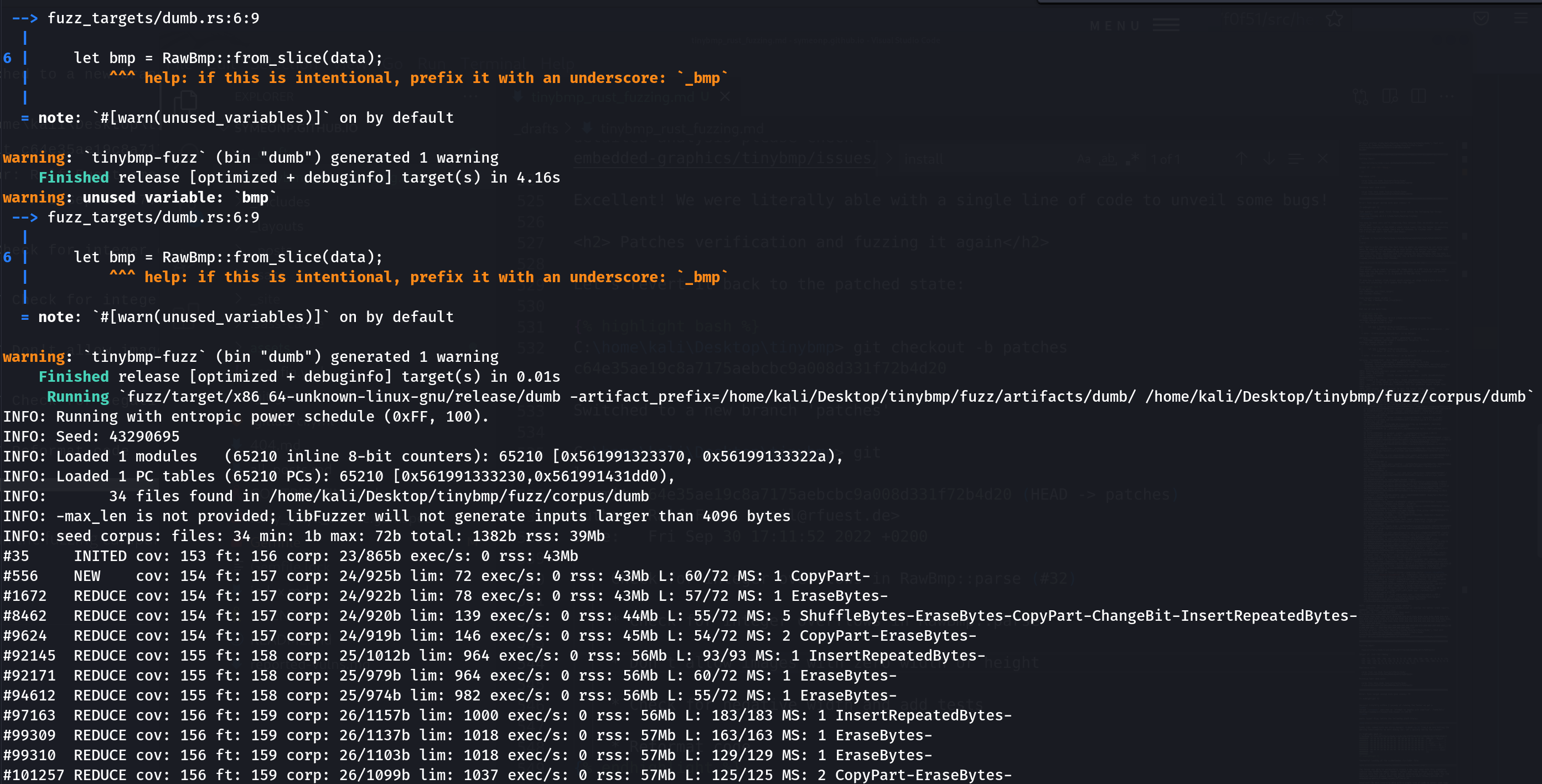
Error: Fuzz target exited with exit status: 77That doesn’t look good. First things first notice the following two things:
Compiling tinybmp v0.3.3 (/home/kali/Desktop/tinybmp)
You need to make sure you’re compiling this version (the vulnerable one) and not latest one! Furthermore looking at the ASAN’s stack trace looks like the fuzzer is panicking and exiting and sure enough there are no refences to tinybmp code.. bummer. Let’s also see what’s the test case about:
$ hexdump -C fuzz/artifacts/dumb/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709 $
Well that’s a bit sketchy, the test case is empty so something is not quite right here. We need to find another way or even better find another function that does something similar to the example and will allow us to target the same functionality. After spending some time reading the docs/examples and the APIs I came across this very interesting one, the RawBmp:
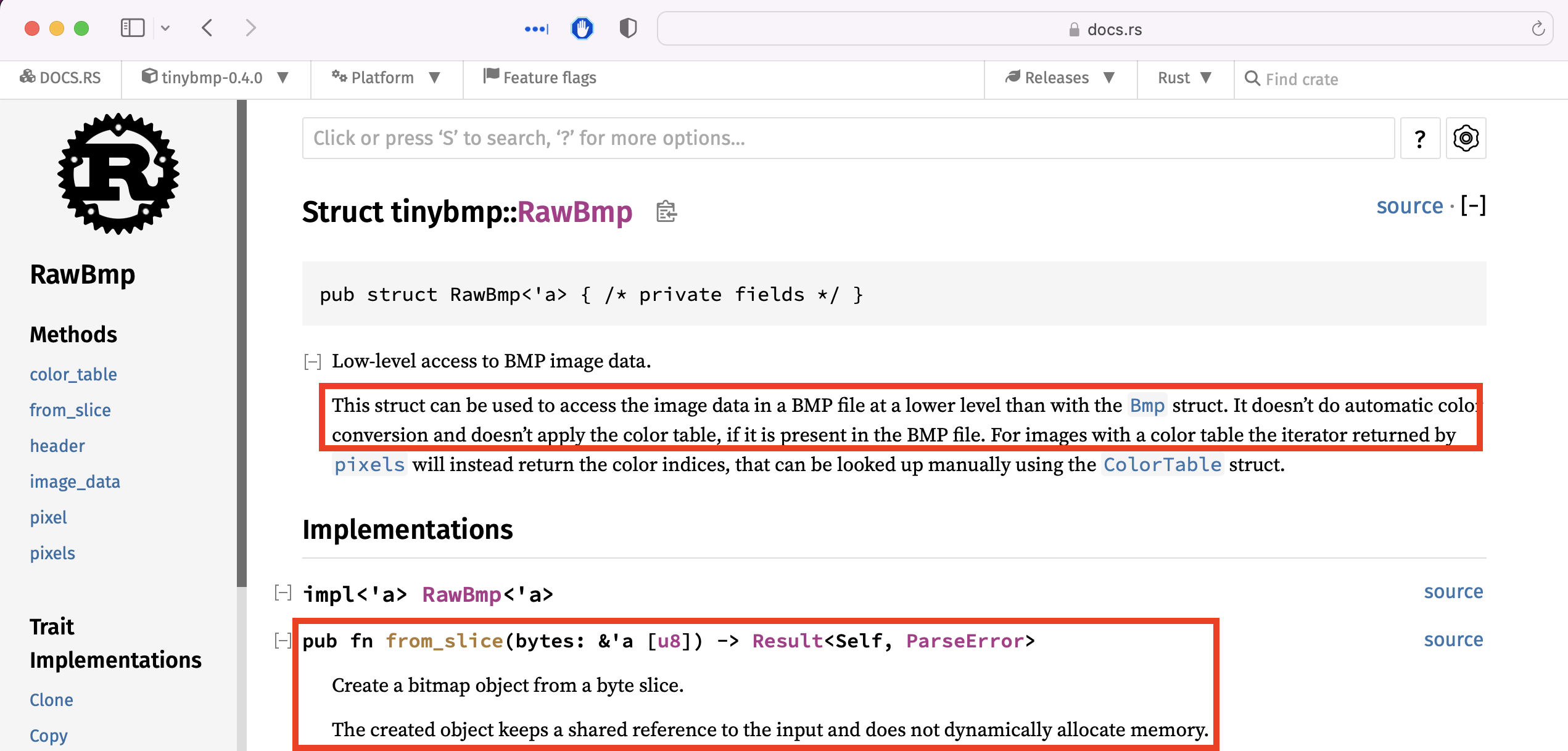
This struct can be used to access the image data in a BMP file at a lower level than with the Bmp struct. It doesn’t do automatic color conversion and doesn’t apply the color table, if it is present in the BMP file.
It even has a method
#![no_main]
use libfuzzer_sys::fuzz_target;
use tinybmp::RawBmp;
fuzz_target!(|data: &[u8]| {
let bmp = RawBmp::from_slice(data);
}); And run it one more time:
$ cargo fuzz run dumb
Compiling tinybmp-fuzz v0.0.0 (/home/kali/Desktop/tinybmp/fuzz)
warning: unused variable: `bmp`
--> fuzz_targets/dumb.rs:6:9
|
6 | let bmp = RawBmp::from_slice(data);
| ^^^ help: if this is intentional, prefix it with an underscore: `_bmp`
|
= note: `#[warn(unused_variables)]` on by default
warning: `tinybmp-fuzz` (bin "dumb") generated 1 warning
Finished release [optimized + debuginfo] target(s) in 0.85s
warning: unused variable: `bmp`
--> fuzz_targets/dumb.rs:6:9
|
6 | let bmp = RawBmp::from_slice(data);
| ^^^ help: if this is intentional, prefix it with an underscore: `_bmp`
|
= note: `#[warn(unused_variables)]` on by default
warning: `tinybmp-fuzz` (bin "dumb") generated 1 warning
Finished release [optimized + debuginfo] target(s) in 0.01s
Running `fuzz/target/x86_64-unknown-linux-gnu/release/dumb -artifact_prefix=/home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/ /home/kali/Desktop/tinybmp/fuzz/corpus/dumb`
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3764774578
INFO: Loaded 1 modules (11479 inline 8-bit counters): 11479 [0x56019247cb50, 0x56019247f827),
INFO: Loaded 1 PC tables (11479 PCs): 11479 [0x56019247f828,0x5601924ac598),
INFO: 34 files found in /home/kali/Desktop/tinybmp/fuzz/corpus/dumb
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: seed corpus: files: 34 min: 1b max: 72b total: 1382b rss: 37Mb
#35 INITED cov: 183 ft: 186 corp: 23/849b exec/s: 0 rss: 40Mb
thread '<unnamed>' panicked at 'attempt to negate with overflow', /home/kali/Desktop/tinybmp/src/header/dib_header.rs:109:52
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
==6871== ERROR: libFuzzer: deadly signal
#0 0x56019221ffe1 in __sanitizer_print_stack_trace /rustc/llvm/src/llvm-project/compiler-rt/lib/asan/asan_stack.cpp:87:3
#1 0x5601922fc3aa in fuzzer::PrintStackTrace() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerUtil.cpp:210:38
#2 0x5601922c5ef5 in fuzzer::Fuzzer::CrashCallback() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:233:18
#3 0x5601922c5ef5 in fuzzer::Fuzzer::CrashCallback() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:228:6
#4 0x7fb12503da9f (/lib/x86_64-linux-gnu/libc.so.6+0x3da9f) (BuildId: 71a7c7b97bc0b3e349a3d8640252655552082bf5)
#5 0x7fb12508957b in __pthread_kill_implementation nptl/./nptl/pthread_kill.c:43:17
#6 0x7fb12503da01 in gsignal signal/../sysdeps/posix/raise.c:26:13
#7 0x7fb125028468 in abort stdlib/./stdlib/abort.c:79:7
#8 0x5601923575e6 in std::sys::unix::abort_internal::h0897be309fb2baa9 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/sys/unix/mod.rs:293:14
#9 0x560192192216 in std::process::abort::hc3bb2bc8d10060de /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/process.rs:2119:5
#10 0x5601922c0293 in libfuzzer_sys::initialize::_$u7b$$u7b$closure$u7d$$u7d$::hfbc7451104c5815a /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:91:9
#11 0x56019234c5ec in std::panicking::rust_panic_with_hook::h76fd95765866f4c4 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:702:17
#12 0x56019234c400 in std::panicking::begin_panic_handler::_$u7b$$u7b$closure$u7d$$u7d$::h60f8b3f90bb7fd93 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:586:13
#13 0x56019234965b in std::sys_common::backtrace::__rust_end_short_backtrace::h483cd9e52367386f /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/sys_common/backtrace.rs:138:18
#14 0x56019234c161 in rust_begin_unwind /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:584:5
#15 0x5601921935a2 in core::panicking::panic_fmt::h44b4db96b14cf253 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/core/src/panicking.rs:142:14
#16 0x56019219346c in core::panicking::panic::h1cd478110c27042a /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/core/src/panicking.rs:48:5
#17 0x56019227f035 in core::num::_$LT$impl$u20$i32$GT$::abs::h3b4f60dd81fb0910 /home/kali/Desktop/tinybmp/src/header/dib_header.rs:109:52
#18 0x56019227f035 in tinybmp::header::dib_header::DibHeader::parse::h11481022451b7bb4 /home/kali/Desktop/tinybmp/src/header/dib_header.rs:109:52
#19 0x560192280f27 in tinybmp::header::Header::parse::h17662c086025b4a3 /home/kali/Desktop/tinybmp/src/header/mod.rs:119:35
#20 0x56019228414d in tinybmp::raw_bmp::RawBmp::from_slice::h62745928fd20c17c /home/kali/Desktop/tinybmp/src/raw_bmp.rs:37:51
#21 0x560192258d16 in dumb::_::run::h93074574f0ae19de /home/kali/Desktop/tinybmp/fuzz/fuzz_targets/dumb.rs:6:15
#22 0x560192258378 in rust_fuzzer_test_input /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:224:17
#23 0x5601922bb62f in libfuzzer_sys::test_input_wrap::_$u7b$$u7b$closure$u7d$$u7d$::h6b2b51dabd6d08ff /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:61:9
#24 0x5601922bb62f in std::panicking::try::do_call::h2b6b2fecd8b0ff94 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:492:40
#25 0x5601922c04c7 in __rust_try libfuzzer_sys.4efe2baf-cgu.0
#26 0x5601922bf848 in std::panicking::try::hf3b7ef749ee396d0 /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panicking.rs:456:19
#27 0x5601922bf848 in std::panic::catch_unwind::hef97c053185a011b /rustc/40336865fe7d4a01139a3336639c6971647e885c/library/std/src/panic.rs:137:14
#28 0x5601922bf848 in LLVMFuzzerTestOneInput /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/src/lib.rs:59:22
#29 0x5601922c6429 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:612:15
#30 0x5601922cd85f in fuzzer::Fuzzer::RunOne(unsigned char const*, unsigned long, bool, fuzzer::InputInfo*, bool, bool*) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:514:22
#31 0x5601922ce6b2 in fuzzer::Fuzzer::MutateAndTestOne() /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:758:25
#32 0x5601922cf437 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile> >&) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerLoop.cpp:903:21
#33 0x5601922e4fe4 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerDriver.cpp:912:10
#34 0x5601921939d2 in main /home/kali/.cargo/registry/src/github.com-1ecc6299db9ec823/libfuzzer-sys-0.4.5/libfuzzer/FuzzerMain.cpp:20:30
#35 0x7fb125029209 in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
#36 0x7fb1250292bb in __libc_start_main csu/../csu/libc-start.c:389:3
#37 0x560192193b10 in _start (/home/kali/Desktop/tinybmp/fuzz/target/x86_64-unknown-linux-gnu/release/dumb+0x72b10) (BuildId: b139364c0b8f8dbd36bbe24a5dc1ea26395b8666)
NOTE: libFuzzer has rudimentary signal handlers.
Combine libFuzzer with AddressSanitizer or similar for better crash reports.
SUMMARY: libFuzzer: deadly signal
MS: 1 CMP- DE: "\000\000\000\200"-; base unit: 3f7608254f3fb2a41b60936bd3b177b690ab1143
0x42,0x4d,0x6e,0x6a,0x6a,0x28,0x10,0x0,0x0,0x4d,0x6a,0x6a,0x6a,0x6a,0x28,0x0,0x0,0x0,0xb0,0x95,0x95,0x95,0x0,0x0,0x0,0x80,0x0,0x0,0x8,0x0,0x0,0x0,0x0,0x0,0x6a,0x6a,0x6a,0x0,0x0,0x0,0x0,0x6a,0x6a,0x6a,0x2d,0x0,0x0,0x0,0x0,0x0,0x0,0x0,0x6a,0x7f,
BMnjj(\020\000\000Mjjjj(\000\000\000\260\225\225\225\000\000\000\200\000\000\010\000\000\000\000\000jjj\000\000\000\000jjj-\000\000\000\000\000\000\000j\177
artifact_prefix='/home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/'; Test unit written to /home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/crash-81481a4874f3dc166c900050e181757698fda554
Base64: Qk1uamooEAAATWpqamooAAAAsJWVlQAAAIAAAAgAAAAAAGpqagAAAABqamotAAAAAAAAAGp/
────────────────────────────────────────────────────────────────────────────────
Failing input:
fuzz/artifacts/dumb/crash-81481a4874f3dc166c900050e181757698fda554
Output of `std::fmt::Debug`:
[66, 77, 110, 106, 106, 40, 16, 0, 0, 77, 106, 106, 106, 106, 40, 0, 0, 0, 176, 149, 149, 149, 0, 0, 0, 128, 0, 0, 8, 0, 0, 0, 0, 0, 106, 106, 106, 0, 0, 0, 0, 106, 106, 106, 45, 0, 0, 0, 0, 0, 0, 0, 106, 127]
Reproduce with:
cargo fuzz run dumb fuzz/artifacts/dumb/crash-81481a4874f3dc166c900050e181757698fda554
Minimize test case with:
cargo fuzz tmin dumb fuzz/artifacts/dumb/crash-81481a4874f3dc166c900050e181757698fda554
────────────────────────────────────────────────────────────────────────────────
Error: Fuzz target exited with exit status: 77Success! Literally within 3 seconds of running the fuzzer we get a
thread '
panic issue! Also, notice the following stack traces:

Looks like indeed with our dirty harness dumb.rs line 6 we are hitting the parsing functionality we were aiming for. Let’s quickly verify the crasher:
$ hexdump -C fuzz/artifacts/dumb/crash-53bc3fdf92ab10167c288b0b52b5228361deab14
00000000 42 4d 6e 6a 68 28 00 04 00 4d 6a 6a 6a 4a 28 00 |BMnjh(...MjjjJ(.|
00000010 00 00 4d 38 00 00 00 00 00 80 00 00 18 00 00 00 |..M8............|
00000020 00 00 6a 6a 6a 34 00 00 00 00 1a 6a 01 00 00 00 |..jjj4.....j....|
00000030 00 00 04 6a 6a 6a 4a 28 00 00 00 4d 38 00 00 00 |...jjjJ(...M8...|
00000040 00 00 00 00 00 18 00 00 00 00 00 6a 6a 6a 34 00 |...........jjj4.|
00000050 00 00 00 1a 6a 01 00 00 00 00 00 04 6a 6a 6a 6a |....j.......jjjj|
00000060 6a |j|
00000061Fantastic! Looking at the header.rs file:
the fuzzer was able to successfully create a new test case with this signature (notice the BM magic header 2 bytes) and find an issue. I’d also like to mention here that one of my issues was an interesting out of bounds read. For the detailed analysis please check the github issue here.
Excellent! We were literally able with a single line of code to unveil some bugs!
Coverage
Remember that it’s very essential to check coverage, so let’s do that. Before proceeding make sure to install the llvm-profdata for the rust toolchain. Let’s run the coverage command:
cargo fuzz coverage dumb
-- snip --
Generating coverage data for "4bc861e1c2b691badd48e0533504794b2364d6ed"
warning: unused variable: `bmp`
--> fuzz_targets/dumb.rs:6:9
|
6 | let bmp = RawBmp::from_slice(data);
| ^^^ help: if this is intentional, prefix it with an underscore: `_bmp`
|
= note: `#[warn(unused_variables)]` on by default
warning: `tinybmp-fuzz` (bin "dumb") generated 1 warning (run `cargo fix --bin "dumb"` to apply 1 suggestion)
Finished release [optimized + debuginfo] target(s) in 0.02s
Running `target/x86_64-unknown-linux-gnu/release/dumb -artifact_prefix=/home/kali/Desktop/tinybmp/fuzz/artifacts/dumb/ /home/kali/Desktop/tinybmp/fuzz/corpus/dumb/4bc861e1c2b691badd48e0533504794b2364d6ed`
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 4142636592
INFO: Loaded 1 modules (61528 inline 8-bit counters): 61528 [0x56533c7e85e0, 0x56533c7f7638),
INFO: Loaded 1 PC tables (61528 PCs): 61528 [0x56533c7f7638,0x56533c8e7bb8),
target/x86_64-unknown-linux-gnu/release/dumb: Running 1 inputs 1 time(s) each.
Running: /home/kali/Desktop/tinybmp/fuzz/corpus/dumb/4bc861e1c2b691badd48e0533504794b2364d6ed
Executed /home/kali/Desktop/tinybmp/fuzz/corpus/dumb/4bc861e1c2b691badd48e0533504794b2364d6ed in 0 ms
***
*** NOTE: fuzzing was not performed, you have only
*** executed the target code on a fixed set of inputs.
***
Merging raw coverage data...
Coverage data merged and saved in "/home/kali/Desktop/tinybmp/fuzz/coverage/dumb/coverage.profdata".Ok, coverage data has been saved, let’s try to convert and view it:
$ cd coverage/dumb
$ ls
coverage.profdata raw
$ cargo cov -- show -Xdemangler=rustfilt ../../target/x86_64-unknown-linux-gnu/release/dumb \
--format=html \
-instr-profile=coverage.profdata > index.html
Looking at the raw_bmp.rs reveals that lines 73-104 got never hit. Within the RawBmp trait implemention we can see that ParseError::InvalidImageDimensions got never hit, including all those function in the above image.
Patches verification and 2nd round of fuzzing
Let’s revert it back to the patched state:
C:\home\kali\Desktop\tinybmp> git checkout -b patched c64e35ae19c8a7175aebcbc9a008d331f72b4d20
Switched to a new branch 'patched'
C:\home\kali\Desktop\tinybmp> git log
commit c64e35ae19c8a7175aebcbc9a008d331f72b4d20 (HEAD -> patches)
Author: Ralf Fuest <mail@rfuest.de>
Date: Fri Sep 30 17:11:52 2022 +0200
Check for integer overflows in RawBmp::parse (#32)
* Check for integer overflows in RawBmp::parse
* Don't allow images with zero width or height
* Check for negative width and add tests
* Reformat codeand re-run the fuzzing campaign for five minutes..
cargo fuzz run dumb -- -max_total_time=300
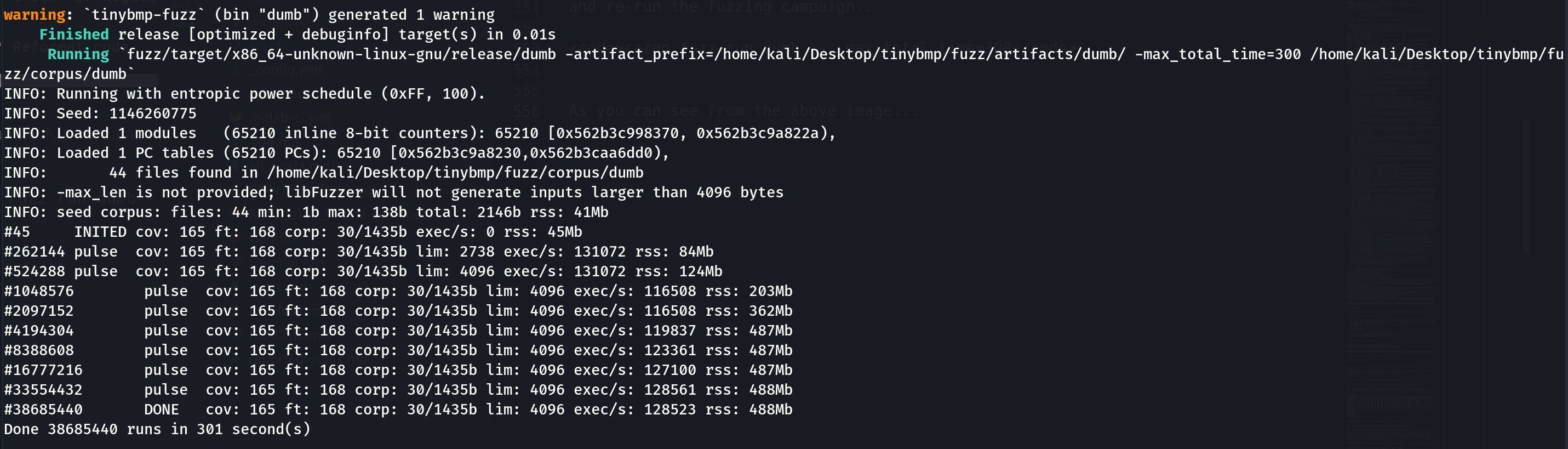
Hmm! As you can see from the above image looks like the project mainteners have done a great job - they’ve added lots of verification and improved header parsing so that dumb fuzzing won’t find any low-hanging fruits..
Time for us to skill up and move to smart fuzzing!
Structured Aware Fuzzing
Now it’s time to invest some time a bit more and get a better understanding of the parsing mechanism. We will be using the harness provided here. Create a new project and paste the harness from the above link:
cargo fuzz add structured
Before starting make sure you add those extra depedencies to your main Cargo.toml:
[dependencies]
libfuzzer-sys = "0.4"
embedded-graphics = "0.7.1"
embedded-graphics-core = "0.3.3"
arbitrary = "1.2.0"
rand = "0.8.5"Let’s try to break down and understand what this harness does.
Lines 4-16 define our modules. The most interesting one that we will be using is the arbitrary one which as per documentation:
This crate is primarily intended to be combined with a fuzzer like libFuzzer and cargo-fuzz or AFL, and to help you turn the raw, untyped byte buffers that they produce into well-typed, valid, structured values. This allows you to combine structure-aware test case generation with coverage-guided, mutation-based fuzzers.
We will be also importing a few other crates such as the Point and rand::rngs::StdRng because we need them for the harness.
4 use arbitrary::{Arbitrary, Unstructured};
5 use embedded_graphics_core::geometry::Point;
6 use libfuzzer_sys::fuzz_target;
7 use rand::rngs::StdRng;
8 use rand::{RngCore, SeedableRng};
9 use std::num::{NonZeroI8, NonZeroU8};
10 #[cfg(not(fuzzing))]
11 use std::{
12 fs::{read_dir, File},
13 io::Read,
14 };
15 use tinybmp::Bpp::*;
16 use tinybmp::{Bpp, RawBmp};
17
18 #[allow(non_camel_case_types)]
19 #[derive(Debug, Copy, Clone, PartialOrd, PartialEq)]Line 18 #[allow(non_camel_case_types)] disables the camel case warnings.
Lines 21-26 create a new enum type DibType that is required so we can initialise the header size. Notice also how on line 19 we are automatically implementing the #[derive(Debug, Copy, Clone, PartialOrd, PartialEq)] traits for the DibType structure. If we don’t do that, the harness won’t compile:
20 #[repr(u8)]
21 enum DibType {
22 DIB_INFO_HEADER_SIZE = 40,
23 DIB_V3_HEADER_SIZE = 56,
24 DIB_V4_HEADER_SIZE = 108,
25 DIB_V5_HEADER_SIZE = 124,
26 }
27 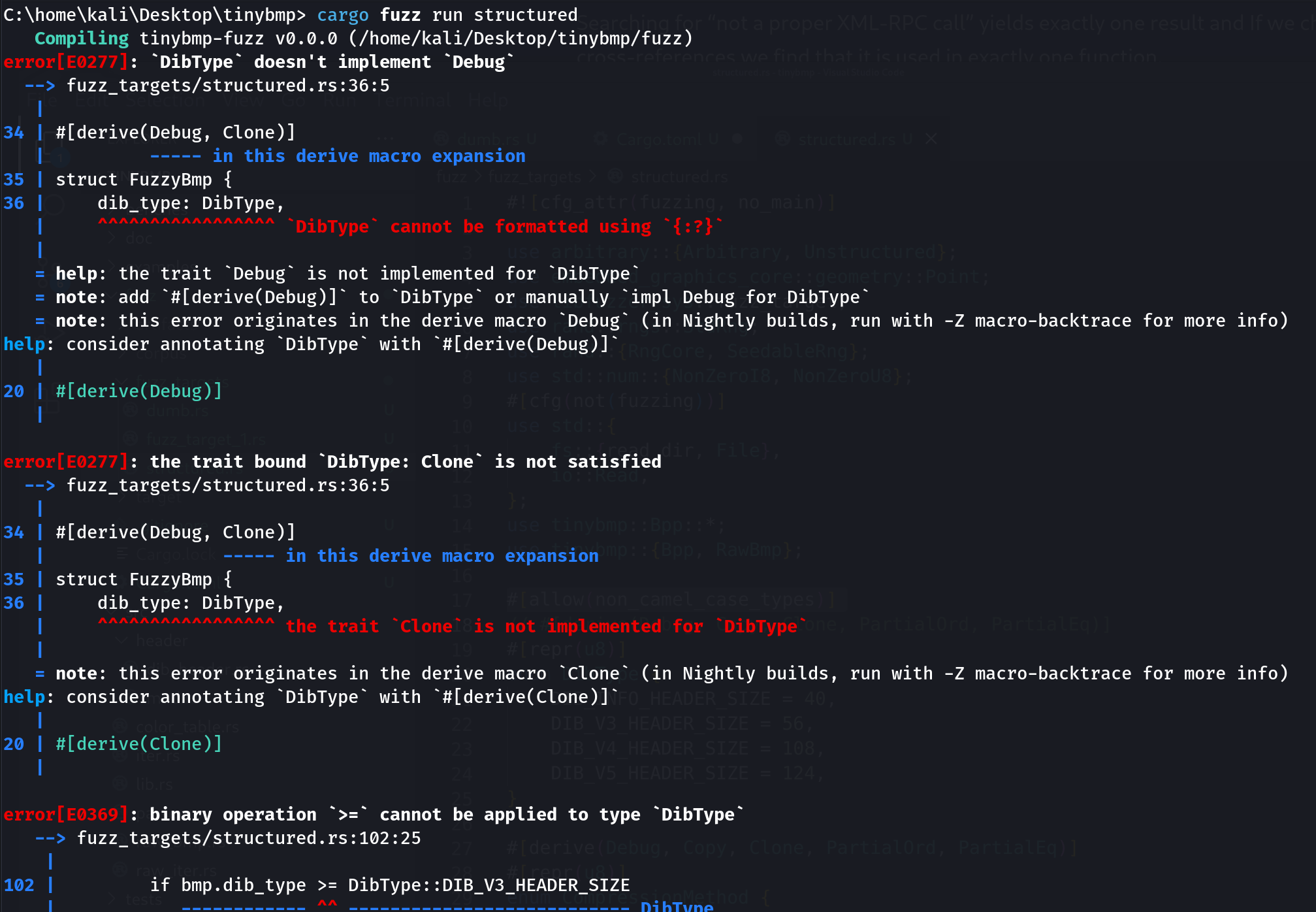
Moving on:
28 #[derive(Debug, Copy, Clone, PartialOrd, PartialEq)]
29 #[repr(u8)]
30 enum CompressionMethod {
31 Rgb = 0,
32 Bitfields = 3,
33 }Simillary to the previous struct we again implement the required traits and initialise the Rgb and Bitfields values. The following lines define a more interesting struct, a FuzzyBmp one.
35 #[derive(Debug, Clone)]
36 struct FuzzyBmp {
37 dib_type: DibType,
38 bpp: Bpp,
39 compress: CompressionMethod,
40 colours_used: u32,
41 width: u32,
42 height: i32,
43 mask_red: u32,
44 mask_green: u32,
45 mask_blue: u32,
46 mask_alpha: u32,
47 // TODO compute at arb time
48 colour_table: Box<[u8]>,
49 image_data: Box<[u8]>,
50 }If you’ve previously played with Rust you will immediately recognise the u32 and i32 which stands for unsigned and signed integers. In addition to those, we are using the Box and <u8> types so what are they?

It should be noted that some of these values are taken from the dib_header.rs code which will be used for creating a smart-ish BMP file:
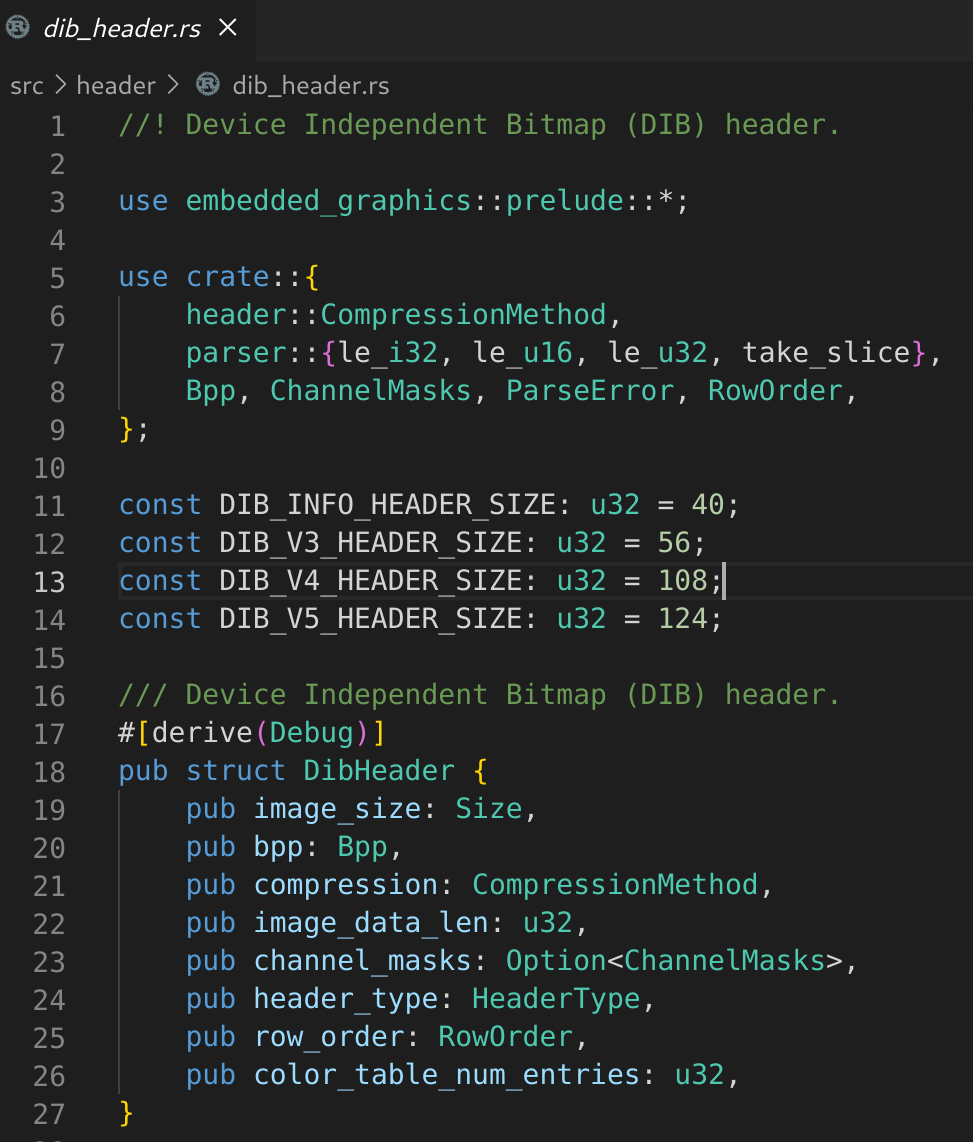
There are a few variables that need our attention here. libFuzzer supports only the primitive variables (signed/unsigned integers such i32/u32) as well as chars. However in this struct we have defined some custom ones such as the DibType and Bpp. Later in this section we will see how we will implement the arbitrary trait in order for libfuzzer to understand these custom variables.
52 impl From<FuzzyBmp> for Vec<u8> {
53 fn from(bmp: FuzzyBmp) -> Self {
54 let mut res = Vec::new();
55
56 // --- HEADER ---
57
58 // header magic
59 res.extend_from_slice(b"BM");
60
61 // size; calculated later
62 let size_marker = res.len();
63
64 // reserved data
65 res.extend_from_slice(&0u16.to_le_bytes());
66 res.extend_from_slice(&0u16.to_le_bytes());
67
68 // image data offset; calculated later
69 let data_ptr_marker = res.len();
70 From Rust’s documentation:
From
The From trait allows for a type to define how to create itself from another type, hence providing a very simple mechanism for converting between several types. There are numerous implementations of this trait within the standard library for conversion of primitive and common types.
In short, on lines 52-53 we are implementing the Vec<u8> vector. Then on line 54, we declare a new mutable vector, and we slowly start filling the values for the BMP file format. Since this is a Vec<u8> we will be using Vec::extend_from_slice to append to the vector.
Then on 59-69 we start crafting the header. Before moving on with the DIB header let’s panic on purpose the fuzzer and print so far the contents so we can verify we are on the right track:
println!("{:?}", res);
panic!("printing contents of res, exiting.");and running the fuzzer yeilds the following:
Output of `std::fmt::Debug`:
FuzzyBmp {
dib_type: DIB_INFO_HEADER_SIZE,
bpp: Bits16,
compress: Rgb,
colours_used: 0,
width: 4,
height: 126,
mask_red: 4294967295,
mask_green: 4286513151,
mask_blue: 4294902016,
mask_alpha: 65535,
colour_table: [],
image_data: [.....snip....]
}So far, so good. We’ve managed to correctly populate the right values for the image header. Let’s continue with the DIB header:
71 // --- DIB Header ---
72
73 // length
74 res.extend_from_slice(&(bmp.dib_type as u32).to_le_bytes());
75
76 // width, height
77 res.extend_from_slice(&bmp.width.to_le_bytes());
78 res.extend_from_slice(&bmp.height.to_le_bytes());
79
80 // color planes -- unused
81 res.extend_from_slice(&0u16.to_le_bytes());
82
83 // bpp
84 res.extend_from_slice(&(bmp.bpp.bits()).to_le_bytes());
85
86 // compression method
87 res.extend_from_slice(&(bmp.compress as u32).to_le_bytes());
88
89 // image data len
90 res.extend_from_slice(&u32::try_from(bmp.image_data.len()).unwrap().to_le_bytes());
91
92 // pels per meter x + y -- unused
93 res.extend_from_slice(&0u32.to_le_bytes());
94 res.extend_from_slice(&0u32.to_le_bytes());
95
96 // colours used
97 res.extend_from_slice(&bmp.colours_used.to_le_bytes());
98
99 // colours important -- unused
100 res.extend_from_slice(&0u32.to_le_bytes());
101
102 // channel masks, if we meet the described conditions
103 if bmp.dib_type >= DibType::DIB_V3_HEADER_SIZE
104 && bmp.compress == CompressionMethod::Bitfields
105 {
106 res.extend_from_slice(&bmp.mask_red.to_le_bytes());
107 res.extend_from_slice(&bmp.mask_green.to_le_bytes());
108 res.extend_from_slice(&bmp.mask_blue.to_le_bytes());
109 res.extend_from_slice(&bmp.mask_alpha.to_le_bytes());
110 }
111
112 // colour table
113 res.extend_from_slice(&bmp.colour_table);
114
115 // insert data pointer marker, with corrections
116 res.splice(
117 data_ptr_marker..data_ptr_marker,
118 u32::try_from(res.len() + 2 * core::mem::size_of::<u32>())
119 .unwrap()
120 .to_le_bytes(),
121 );
122
123 // image data
124 res.extend_from_slice(&bmp.image_data);
125
126 // insert total length, with corrections
127 res.splice(
128 size_marker..size_marker,
129 u32::try_from(res.len() + core::mem::size_of::<u32>())
130 .unwrap()
131 .to_le_bytes(),
132 );
133
134 res
135 }
136 }Now let’s move on to arbitrary trait implementation.
137
138 impl<'a> Arbitrary<'a> for FuzzyBmp {
139 fn arbitrary(u: &mut Unstructured<'a>) -> arbitrary::Result<Self> {
140 let dib_type = match u8::arbitrary(u)? % 4 {
141 0 => DibType::DIB_INFO_HEADER_SIZE,
142 1 => DibType::DIB_V3_HEADER_SIZE,
143 2 => DibType::DIB_V4_HEADER_SIZE,
144 3 => DibType::DIB_V5_HEADER_SIZE,
145 _ => unreachable!(),
146 };
147 let bpp = match u8::arbitrary(u)? % 6 {
148 0 => Bits1,
149 1 => Bits4,
150 2 => Bits8,
151 3 => Bits16,
152 4 => Bits24,
153 5 => Bits32,
154 _ => unreachable!(),
155 };
156 let compress = match bool::arbitrary(u)? {
157 false => CompressionMethod::Rgb,
158 true => CompressionMethod::Bitfields,
159 };
160
161 // simply restrict it to 8 bits to keep it within reasonable bounds
162 let width: u32 = NonZeroU8::arbitrary(u)?.get().into();
163 let height: i32 = NonZeroI8::arbitrary(u)?.get().into();
164
165 let mask_red = u.arbitrary()?;
166 let mask_green = u.arbitrary()?;
167 let mask_blue = u.arbitrary()?;
168 let mask_alpha = u.arbitrary()?;
169
170 let mut colours_used = u8::arbitrary(u)? as u32;
171 // bias towards special case
172 let colour_table_num_entries = if colours_used % 4 == 0 && bpp.bits() < 16 {
173 colours_used = 0;
174 (1 << bpp.bits()) as usize
175 } else {
176 colours_used as usize
177 };
178
179 // image data doesn't actually matter; seed and fill
180 let seed = u64::arbitrary(u)?;
181 // rows must be a multiple of 4 bytes, so we do some wacky corrections here
182 let baseline = width * height.unsigned_abs();
183 let data_len = (match bpp {
184 Bits1 => baseline / 8,
185 Bits4 => baseline / 2,
186 Bits8 => baseline,
187 Bits16 => baseline * 2,
188 Bits24 => baseline * 3,
189 Bits32 => baseline * 4,
190 _ => unreachable!(),
191 } as u32
192 + (width * 4 - 1))
193 * (width * 4)
194 / (width * 4);
195 let mut rng = StdRng::seed_from_u64(seed);
196 let mut image_data = vec![0u8; data_len as usize];
197 rng.fill_bytes(image_data.as_mut_slice());
198 let image_data = image_data.into_boxed_slice();
199 Here we are using arbitrary’s Unstructured data, which as per documentation:
An Unstructured helps Arbitrary implementations interpret raw data (typically provided by a fuzzer) as a “DNA string” that describes how to construct the Arbitrary type. The goal is that a small change to the “DNA string” (the raw data wrapped by an Unstructured) results in a small change to the generated Arbitrary instance. This helps a fuzzer efficiently explore the Arbitrary’s input space. Unstructured is deterministic: given the same raw data, the same series of API calls will return the same results (modulo system resource constraints, like running out of memory). However, Unstructured does not guarantee anything beyond that: it makes not guarantee that it will yield bytes from the underlying data in any particular order. You shouldn’t generally need to use an Unstructured unless you are writing a custom Arbitrary implementation by hand, instead of deriving it. Mostly, you should just be passing it through to nested Arbitrary::arbitrary calls.
We start off with the DibType where one of the DIB_INFO_HEADER_SIZE, DIB_V3_HEADER_SIZE, DIB_V4_HEADER_SIZE, DIB_V5_HEADER_SIZE values are randomly selected. Then the same smart values are generated for the bpp structure.The compress returns just two values: either Rgb or Bitfields. On lines 164-173 we generate more smartish values that make sense for the parsing. Then on lines 185-197 we generate the data_len which was previously hardcoded. Continuing, on line 195 a new random generator is declared where it will be used to fill random data for the image_data variable.
Lines 200-208 will create a vector filled with random colour table values. We are using an iterator to chain the take() method and fill it only with colour_table_num_entries * 4
200 let colour_table = u
201 .arbitrary_iter()?
202 .flatten()
203 .take(colour_table_num_entries * 4)
204 .collect::<Vec<_>>()
205 .into_boxed_slice();
206 if colour_table.len() != colour_table_num_entries * 4 {
207 return Err(arbitrary::Error::NotEnoughData);
208 }I’ve added a few print methods and here are a few sample examples of the generated data:
println!("{:?}", colour_table);
println!("{:?}", colour_table.len());Would yield:
[0, 255, 255, 0]
4
[11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 255, 255, 255, 255, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 255, 255]
44
[11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 255, 255, 255, 255, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 255, 255]
44
[]
0
[]
0
[]
0
[255, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 255, 255, 255, 255, 219, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255]
64Last bits of the arbitrary implementation we’ve got his Ok result since we need to return a result according to the function signature. Finally we implement the size_hint() function which Returns the bounds on the remaining length of the iterator.
209
210 Ok(Self {
211 dib_type,
212 bpp,
213 compress,
214 colours_used,
215 width,
216 height,
217 mask_red,
218 mask_green,
219 mask_blue,
220 mask_alpha,
221 colour_table,
222 image_data,
223 })
224 }
225
226 fn size_hint(_: usize) -> (usize, Option<usize>) {
227 (25, Some(65536))
228 }
229 }If we run the fuzzer a couple of times we can see that indeed the smart values are properly generated. First run:
FuzzyBmp {
dib_type: DIB_V5_HEADER_SIZE,
bpp: Bits32,
compress: Rgb,
colours_used: 0,
width: 245,
height: -2,
mask_red: 4294967295,
mask_green: 16711701,
mask_blue: 436207360,
mask_alpha: 64512,
colour_table: [],
image_data: [
52,
--snip--
181,
],
}Second run:
FuzzyBmp {
dib_type: DIB_V4_HEADER_SIZE,
bpp: Bits16,
compress: Rgb,
colours_used: 0,
width: 86,
height: -65,
mask_red: 4294967295,
mask_green: 65535,
mask_blue: 402652928,
mask_alpha: 64767,
colour_table: [],
image_data: [
52,
175,
76,
--snip--
149,
114,
],
}We’re getting close finishing the harness. Let’s take a look at the last bits:
230 fn do_fuzz(bmp: FuzzyBmp) {
231 let bmp = Vec::from(bmp);
232 if let Ok(bmp) = RawBmp::from_slice(bmp.as_slice()) {
233 bmp.pixels().for_each(|p| drop(p));
234 for x in 0.. {
235 if bmp.pixel(Point::new(x, 0)).is_none() {
236 break;
237 }
238 for y in 1.. {
239 if bmp.pixel(Point::new(x, y)).is_none() {
240 break;
241 }
242 }
243 }
244 }
245 }On line 231 we create the new bmp Vector (derived from the FuzzyBmp structure) and we use again the familiar RawBmp::from_slice() method (which we used in our dumb fuzzer) but this time we also provide the smart bmp structure. Also notice how looking at the raw_bmp.rs source code the following snippet shows that the pixel() function expects a Point structure as parameter and that’s what we are doing on lines 234-240.
![]()
At this stage let’s print the contents of the FuzzyBmp vector again:
RawBmp { header: Header { file_size: 3233,
image_data_start: 54,
image_size: Size { width: 159, height: 8 },
bpp: Bits16,
image_data_len: 3179,
channel_masks: None,
row_order: BottomUp },
color_type: Rgb555,
color_table: None,
image_data: [226, 81, 8, 28, 132, 44, --snip--]
}This looks more complete, we’ve now calculated dynamically the file_size, as well as the image_data_len.
246
247 fuzz_target!(|data: FuzzyBmp| {
248 do_fuzz(data);
249 });The above code snippet is the bit where cargo-fuzz uses to start mutating data, it calls the previously defined do_fuzz() function.
250
251 #[cfg(not(fuzzing))]
252 extern "C" {
253 fn rust_fuzzer_test_input(bytes: &[u8]) -> i32;
254 }
255
256 #[cfg(not(fuzzing))]
257 fn main() {
258 let dir = std::env::args().skip(1).next().unwrap();
259 let mut content = Vec::new();
260 for entry in read_dir(dir).unwrap() {
261 let entry = entry.unwrap();
262 if !entry.file_type().unwrap().is_file() {
263 continue;
264 }
265 let mut file = File::open(entry.path()).unwrap();
266 content.clear();
267 content.reserve(file.metadata().unwrap().len() as usize);
268 file.read_to_end(&mut content).unwrap();
269 unsafe {
270 rust_fuzzer_test_input(content.as_slice());
271 }
272 }
273 }
274 Finally, these last bits will not be used within cargo-fuzz, if we compile the harness and run it we can see that expects a parameter as a dictionary and reads the contents of the (assuming we provided bmp) files. If we print the contents we can see the following:
[255, 64, 8, 253, 122, 200, 200, 200, 255, 255, 1, 0, 0, 0, 0, 0, 0, 4, 107, 0, 0, 0, 255, 255, 0, 0]
[255, 193, 1, 131, 75, 0, 87, 255, 191, 255, 255, 252, 1, 87, 255, 0, 0, 0, 0, 0, 9, 1, 0, 0, 0, 0, 0, 0, 0, 126, 255, 0, 1, 255, 255, 255, 255, 0]
[255, 193, 1, 131, 87, 255, 191, 255, 63, 255, 252, 1, 255, 255, 0, 0, 0, 0, 0, 0, 9, 1, 0, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 0, 255, 255]We are done with our analysis, let’s try to kick in the fuzzer now:
$ cargo fuzz run structured -- -max_total_time=300
Compiling tinybmp-fuzz v0.0.0 (/home/kali/Desktop/tinybmp/fuzz)
Finished release [optimized + debuginfo] target(s) in 2.48s
Finished release [optimized + debuginfo] target(s) in 0.03s
Running `target/x86_64-unknown-linux-gnu/release/structured -artifact_prefix=/home/kali/Desktop/tinybmp/fuzz/artifacts/structured/ -max_total_time=300 /home/kali/Desktop/tinybmp/fuzz/corpus/structured`
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3975089662
INFO: Loaded 1 modules (79206 inline 8-bit counters): 79206 [0x5600359c55d0, 0x5600359d8b36),
INFO: Loaded 1 PC tables (79206 PCs): 79206 [0x5600359d8b38,0x560035b0e198),
INFO: 416 files found in /home/kali/Desktop/tinybmp/fuzz/corpus/structured
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: seed corpus: files: 416 min: 25b max: 218b total: 18397b rss: 42Mb
#417 INITED cov: 664 ft: 1865 corp: 166/5683b exec/s: 0 rss: 81Mb
#1465 REDUCE cov: 664 ft: 1865 corp: 166/5681b lim: 195 exec/s: 1465 rss: 111Mb L: 37/181 MS: 3 ChangeByte-ChangeBinInt-EraseBytes-
#2436 REDUCE cov: 664 ft: 1865 corp: 166/5679b lim: 202 exec/s: 1218 rss: 138Mb L: 37/181 MS: 1 CrossOver-
#4096 pulse cov: 664 ft: 1865 corp: 166/5679b lim: 216 exec/s: 1365 rss: 192Mb
--snip--
#311445 REDUCE cov: 664 ft: 1868 corp: 168/5731b lim: 3157 exec/s: 1720 rss: 378Mb L: 37/181 MS: 5 CrossOver-ShuffleBytes-EraseBytes-InsertByte-ChangeBit-
#337091 REDUCE cov: 664 ft: 1868 corp: 168/5730b lim: 3410 exec/s: 1719 rss: 378Mb L: 37/181 MS: 1 EraseBytes-
#419743 REDUCE cov: 664 ft: 1868 corp: 168/5729b lim: 4096 exec/s: 1727 rss: 378Mb L: 37/181 MS: 2 ChangeBinInt-EraseBytes-
#441823 REDUCE cov: 664 ft: 1868 corp: 168/5727b lim: 4096 exec/s: 1725 rss: 382Mb L: 44/181 MS: 5 ChangeBinInt-EraseBytes-ChangeBit-ShuffleBytes-EraseBytes-
#445856 REDUCE cov: 664 ft: 1868 corp: 168/5726b lim: 4096 exec/s: 1728 rss: 382Mb L: 37/181 MS: 3 ChangeBinInt-CrossOver-EraseBytes-
#477133 REDUCE cov: 664 ft: 1868 corp: 168/5722b lim: 4096 exec/s: 1722 rss: 382Mb L: 40/181 MS: 2 ChangeBit-EraseBytes-
#479444 REDUCE cov: 664 ft: 1868 corp: 168/5721b lim: 4096 exec/s: 1724 rss: 382Mb L: 37/181 MS: 1 EraseBytes-
#495684 REDUCE cov: 664 ft: 1868 corp: 168/5718b lim: 4096 exec/s: 1721 rss: 382Mb L: 43/181 MS: 5 ChangeBit-CMP-ChangeBinInt-ShuffleBytes-EraseBytes- DE: "x\000"-
#519634 DONE cov: 664 ft: 1868 corp: 168/5718b lim: 4096 exec/s: 1726 rss: 382Mb
###### Recommended dictionary. ######
"\001\000\000\000\000\000\000\004" # Uses: 44855
"x\000" # Uses: 1145
###### End of recommended dictionary. ######
Done 519634 runs in 301 second(s)Unfortunately this improved harness didn’t yield any new bugs!
Coverage round 2
Let’s do this one more time running the smart-ish fuzzer:
cargo fuzz coverage structured
and after converting the data to HTML we get:
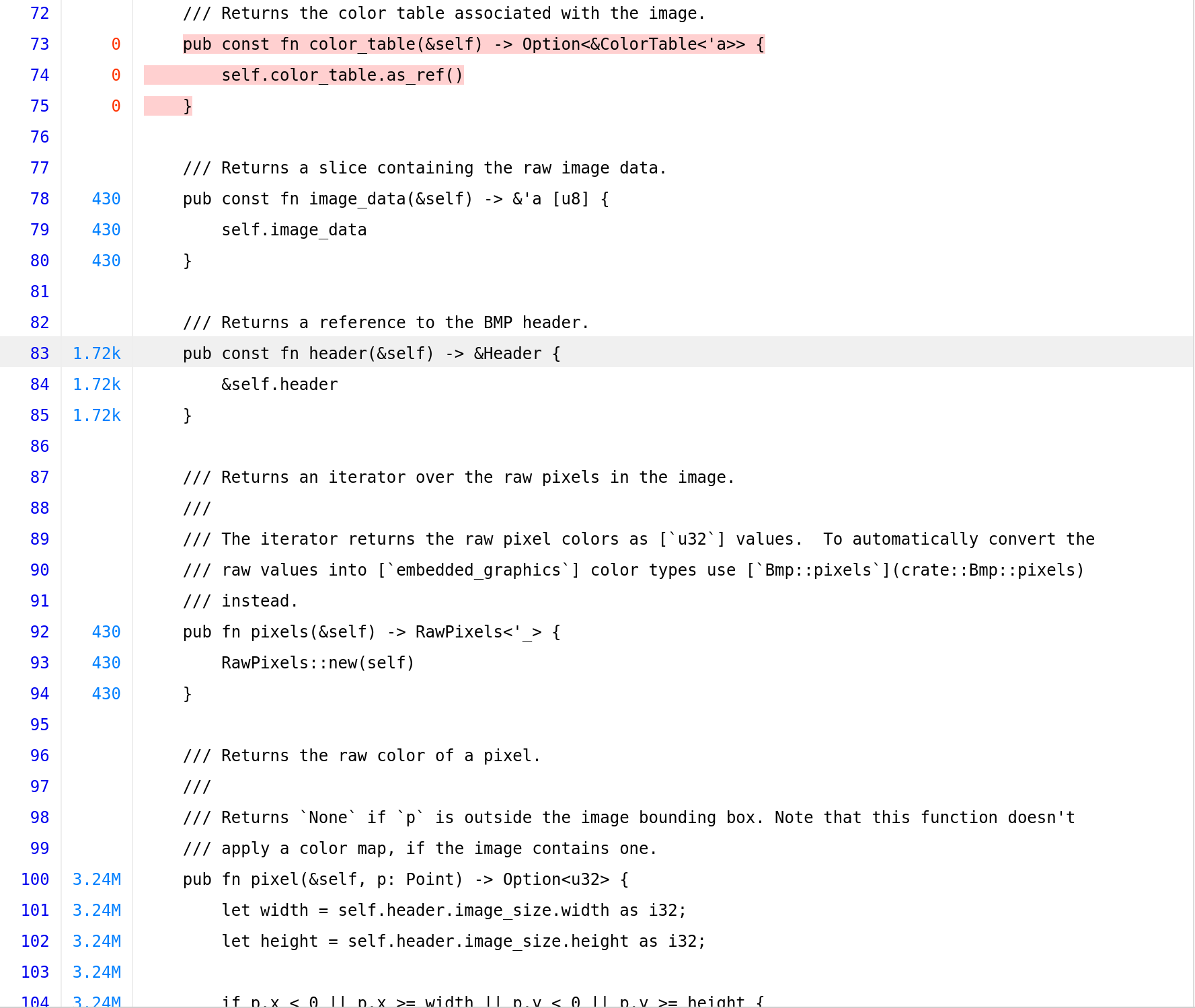
Fantastic! We did a lot of effort but as you can see this time we were able to hit all those functions (1.7k and 3.24 million times!) and get decent coverage.
Conclusion
We started with finding a fun target, created a dumb fuzzer and found some bugs with it. Then, we moved on with a smart-ish/structured aware approach and despite the fact were not able to uncover new bugs, we learnt how to mess around with arbitrary trait, and we dug a bit deeper to the internals of the project. Hope you enjoyed it and learnt something - I definitely did!
References
[1] Earn $200K by fuzzing for a weekend: Part 1
[2] Fuzzing with cargo-fuzz